StarRocks is an OLAP database enabling blazing fast, unified data analytics for customers worldwide. StarRocks powers data analytics in various scenarios without the need for complicated data preprocessing. After more than one year's development, StarRocks 2.0 made its debut in early 2022 with new features, delivering a unified, lightning-fast data analytics experience to customers.
2021 in Retrospect: Improvements and Breakthroughs
At the end of January 2021, StarRocks 1.0 on vectorized execution engine was officially released. This newly-launched OLAP product can run blazing fast single-table queries, which is comparable to world's fastest open source OLAP products. Throughout 2021, we have been committed to accelerating single-table queries. In StarRocks 2.0, we have made revolutionary achievements, including CPU instruction optimization and low-cardinality string query optimization based on global dictionaries. These features enable StarRocks 2.0 to deliver a single-table query performance twice that of its predecessor StarRocks 1.0 and far better than world's fastest OLAP database systems. Since the debut, contributors of the StarRocks community have demonstrated enormous interest in trialing StarRocks 2.0.
The following table provides benchmark results between StarRocks 2.0 and ClickHouse 21.9 and between StarRocks 2.0 and StarRocks 1.19.
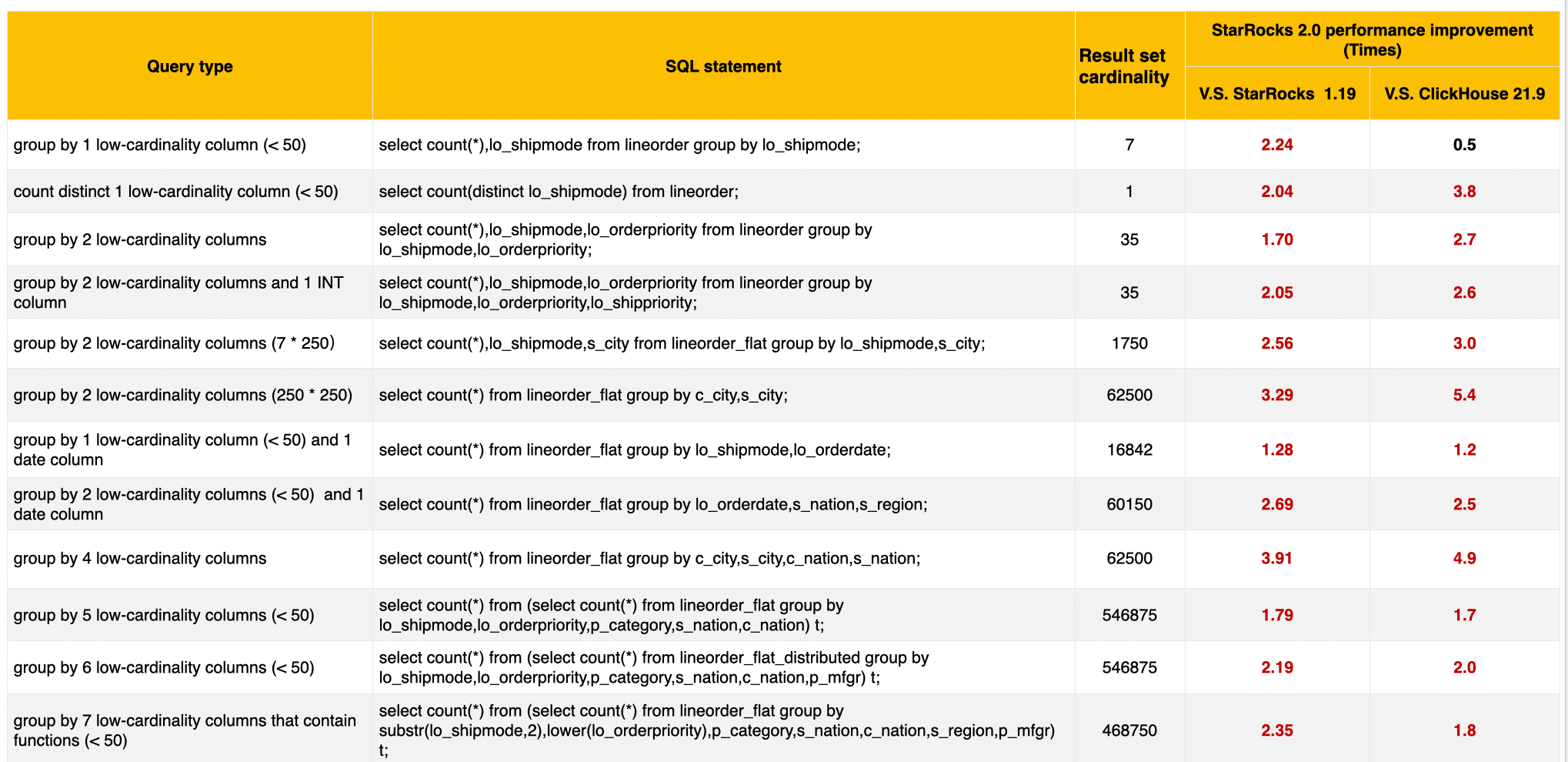
* Test environment: StarRocks 1.19 and 2.0 with one FE and three BE nodes; ClickHouse 21.9 with three nodes, which have the same configurations as StarRocks nodes.
StarRocks significantly improves the efficiency of multi-table queries. Previously, data engineers must combine multiple tables into flat tables before data analysis. Behind this, database engineers have to withstand a lot of bitter workloads which other people do not know. To resolve this issue, in December 2019, StarRocks started a journey of developing a cost-based optimizer (CBO) to achieve ultra-fast analytics on multiple tables without the need for complex preprocessing. With relentless efforts throughout 2020 and 2021, the CBO of StarRocks 2.0 becomes powerful and stable enough to handle complex multi-table queries. For join queries, the optimized CBO delivers a performance twice that of the previous version and five to ten times that of other open-source products. StarRocks has made breakthroughs in both single-table and multi-table queries.
Traditional OLAP systems use the merge-on-read mode to update data, which is not the best solution because it pursues data loading efficiency at the cost of query performance. As real-time data update requirements keep rising, this model no longer lives up to expectations. In May 2021, StarRocks began the research on a new model and officially introduces the primary key model in StarRocks 2.0 to update data in delete-and-insert mode. This innovation enhances query performance by three to ten times in real-time update scenarios.
In June 2021, StarRocks began to develop the pipeline execution engine, which is designed to dramatically improve concurrency and facilitate complex queries on multi-core machines. StarRocks fulfilled this task from scratch and did a lot of explorations that have never been done before. The pipeline execution engine will be packaged into StarRocks 2.1. We welcome you to try out this new feature and give us some feedback.
In the past six months, StarRocks has been sparing no effort in reinforcing stability because stability is fundamental to high concurrency. In StarRocks 2.0, we have redesigned the memory management scheme to prevent Out Of Memory (OOM) errors in BE nodes, significantly improving stability.
In September 2021, StarRocks opened its source code and is committed to building a global community. The following statistics demonstrate the active participation of StarRocks in the community.
- Within the 135 days after the code is open, the community has attracted 75 contributors and more than 40 monthly active contributors, and received 1,238 commits and more than 2,000 GitHub stars.
- We have organized eight community meetups online and offline, attracting over 5,000 people.
- The community has attracted 85 large customers (with a valuation or a market value of over 1 billion dollars) to use StarRocks, and the number is still growing.
Outlook into the Future: Highlights and R&D Directions
Resource Management
StarRocks has outstanding performance in various data analytics scenarios. As customers deploy more services on StarRocks, they hope that different business units can run in the same cluster without affecting each other.
StarRocks will introduce a new resource management mechanism to provide separate resource groups for different business units. This mechanism guarantees sufficient resource quotas and isolated resources for business units. This way, different services can run on the same cluster, which simplifies O&M and improves cluster resource utilization.
Materialized Views with JOINs
Recent surveys show that customers have urgent demands for materialized views with JOINs.
Materialized views are used to accelerate queries. StarRocks provides real-time materialized views and automatically selects suitable materialized views to rewrite or reroute incoming queries. Real-time materialized views enable data in materialized views to be synchronously updated with any changes in base tables. Automatic rerouting means that StarRocks can estimate the costs of various query plans and select the most appropriate one to accelerate queries. The acceleration is also transparent to users.
In 2022, StarRocks will support materialized views with JOINs and add more operators to materialized views. These flexible materialized views will simplify the entire process of data processing, which used to involve complex data development. Materialized views enable data analysts to obtain the final data model by creating various types of materialized views, making data analytics easier and more convenient.
In addition, StarRocks will provide intelligent materialized views to recommend materialized views based on customers' query behavior to accelerate queries.
Decoupled Storage and Compute
In the earlier versions of StarRocks, compute and storage are coupled for excellent query performance. However, this architecture cannot achieve on-demand resource allocation and may result in unnecessary costs.
As infrastructure-as-a-service (IaaS) gains popularity, OLAP databases have also entered the booming cloud computing era. By leveraging the scalability offered by cloud computing, customers of OLAP systems can expect flexible resource allocation and lower resource costs.
In 2022, StarRocks will implement a new architecture where storage and compute are decoupled. This new architecture supports offline analytics in parallel with real-time analytics and can be deployed on public, private, and multiple clouds.
We expect to work with partners in the community to develop an architecture that suits varied analytics requirements.
Lightning-Fast Analytics on Data Lakes
Currently, StarRocks serves more like a data warehouse. Customers import high-value data from data lakes to StarRocks for ultra-fast data analytics, and store low-value raw data in data lakes. Customers have requirements for both ultra-fast analytics on data in data lakes and federated queries against data in data lakes and data warehouses.
In 2022, StarRocks will press ahead with its endeavors to enhance data lake analytics capabilities and provide a unified and blazing fast analytics experience for customers.
The StarRocks community has completed the first-phase development of data queries on Apache Iceberg, with the collaboration from Alibaba Cloud. Test results show that StarRocks offers a 5X performance improvement compared to Trino. In the future, the StarRocks community will extend its support for Apache Hudi and offer more feature enhancements. StarRocks sincerely invites more people to build the community together.
In January 2022, Alibaba Cloud E-MapReduce (EMR) will start the public preview on StarRocks. In the future, StarRocks will cooperate with more cloud service providers. Stay tuned.
Unified Stream and Batch Processing
StarRocks offers blazing fast data processing and analytics. A large number of customers want to use StarRocks to process workflows that are currently run on Apache Spark™ or Apache Flink®. Many of them have already started the journey.
StarRocks will enhance batch and stream processing in 2022 and implement unified stream and batch processing across hundreds of nodes. This way, customers' raw data can be processed and analyzed all in StarRocks. This guarantees a one-stop, unified, and blazing fast data processing and analytics experience.
In 2022, StarRocks will unswervingly pursue the goal of becoming a world-leading analytical database that delivers ultra-fast query and analytics speed for all scenarios. StarRocks was established barely two years ago. We believe in dreaming bigger and aspiring higher and are determined to make StarRocks a world-leading OLAP database.
Apache®, Apache Spark™, Apache Flink®, Apache Hudi, Apache Iceberg, and their logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
